

S3 is still a mistaken entity to many - people will associate it correctly with AWS yet the costs and use cases are generally still confused. This post is aimed at providing an introduction into S3. This will be followed up with a more detailed overview of features and functionality in another post.
What S3 Is
S3 (Simple Storage Service) is AWS's Object Storage offering, it is designed to offer a highly secure, extremely durable, low cost and infinitely scalable cloud repository to store your files.
Resiliency is achieved through replication of the data across multiple devices and facilities , as such S3 allows for upto two facilities to fail whilst still being able to provide access to your data.
S3 is the perfect platform in which to store large amounts of data where an application does not require immediate consistency after an overwrite or which does not need to be accessed all that often. Typical use cases would be as a backup repository , archiving and large content repositories.
What S3 Is Not
S3 is not a place where you can install databases or operating systems due to the nature of the way that it achieves consistency across the multiple platforms across which it replicates.
When you upload a file to S3 it takes time for the file to propagate across the rest of the systems and facilities (Availability Zones in an AWS world). Therefore it takes time for consistency to be achieved whenever you overwrite or delete an object : AWS call this eventual consistency. This model means that S3 is not suited for any requirement where files are required to be overwritten and read immediately back.
Flavours of S3
AWS have created multiple flavours of S3 in order to meet different use cases and price points so before you dive in let's give them a run through. Fortunately for me AWS have already posted the below handy comparisons.
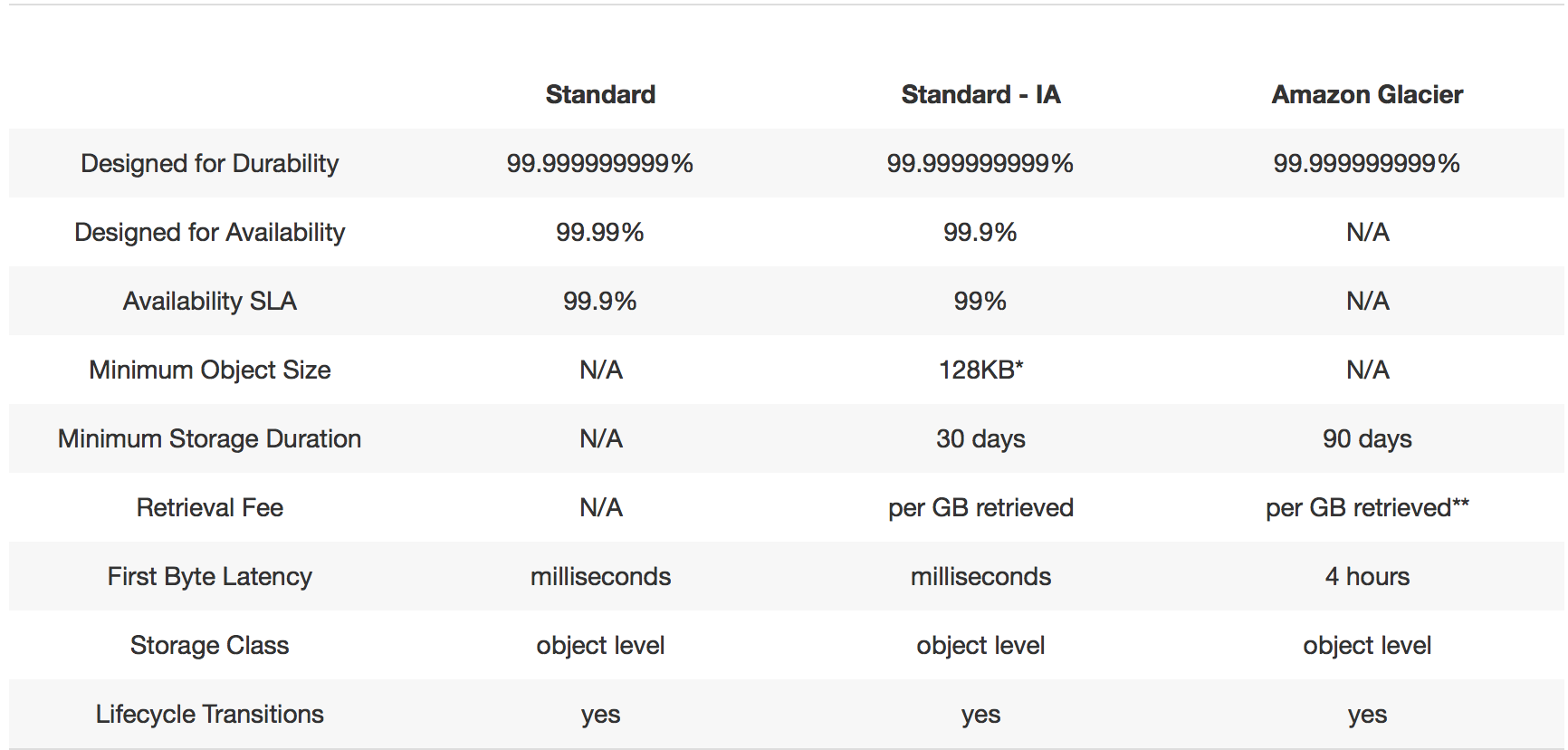
All the above levels offer 11 9's of durability so it is therefore extremely unlikely that you would ever lose a file in S3.
One thing that is worth pointing out is the distinction between "Designed for Availability" and "Availability SLA". Just because a service is designed for 99.99% availability doesn't mean AWS SLA to it. Therefore when making a decision on which service your business should opt for do note the Availability SLA and design your service around that. In order to understand how an availability SLA impacts your uptime click here.
The reason for the differing offerings is mainly down to how frequently you need to access your data. Standard - IA for example offers lower cost storage than Standard but charges per GB retrieved making it ideal if you don't plan on accessing your data very often but need it back quickly when you do. Glacier on the other hand allows for upto 5% of your data to be retrieved per month free of charge but takes 4 hours in order for that data to be retrieved. S3 Standard is therefore somewhere in the middle in that it does not charge retrieval fees but has the highest cost of storing data.
There is also a Reduced Redundancy Storage offering which if you haven't guessed already offers a lower durability (99.99%). This is ideal if the data you are storing isn't important and can be regenerated easily or has no commercial value. Details here
Functionality
Whilst S3 is self proclaimed Simple Storage it does offer some advanced functionality that enable it to be utilised with more confidence within a business.
Amongst the feature set is versioning meaning that every time there is a modification of an object the old version is kept. This will enable you to recover deleted objects but it does have the negative that you are now storing multiple copies of an object thus increasing charges. It's important to note that versioning cannot be disabled once it has been enabled, it can only be suspended.
Server side encryption can also be applied to S3 meaning that if someone were to break into AWS's data center your data will be secure to the tune of AES-256 encryption at no extra cost.
Cross Regional Replication offers resiliency against the loss of an entire region and can be set from the S3 management console. I would suggest looking into options to replicate outside of AWS for true disaster recovery incase of account suspension / breach of credentials and issues arising from utilising a single provider.
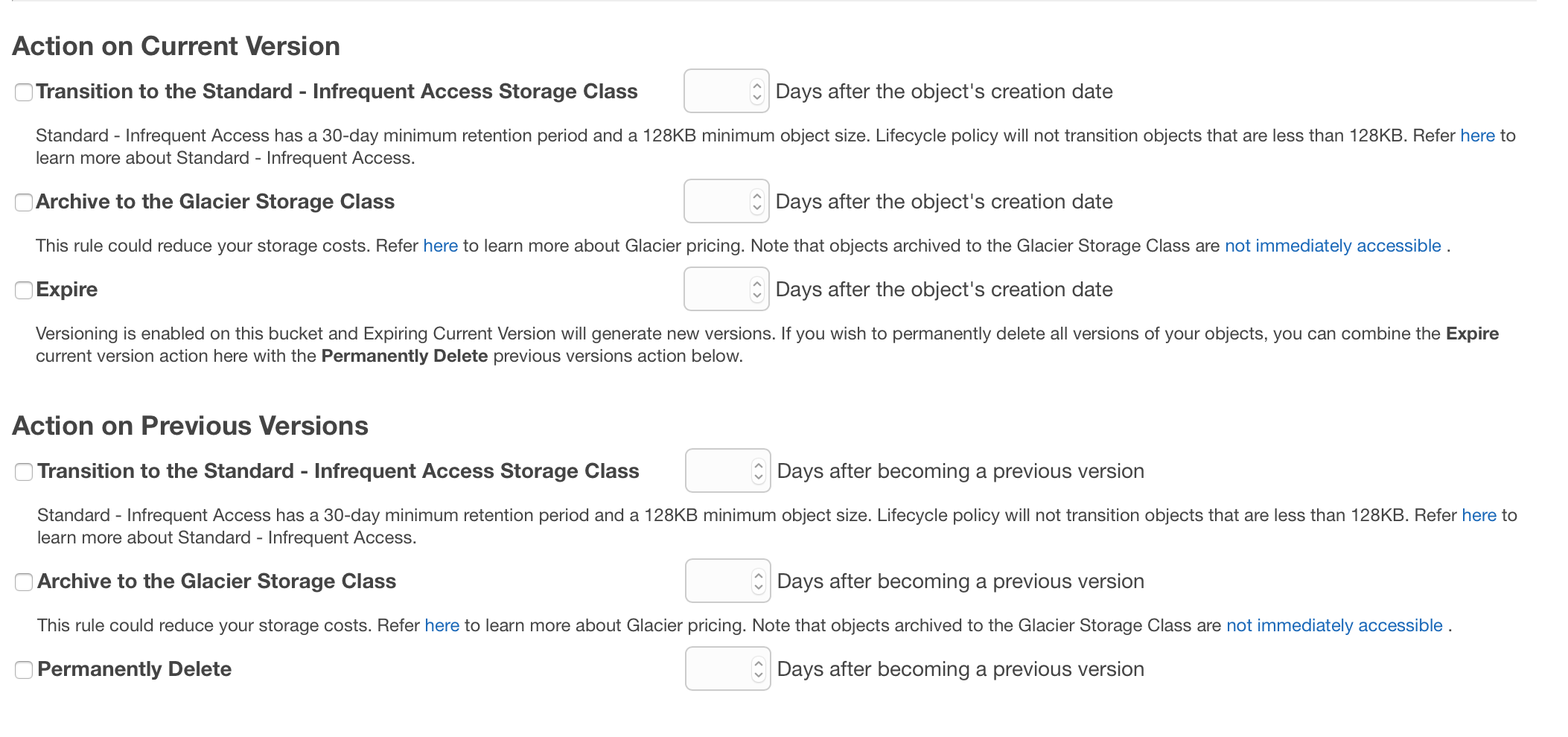
Lifecycle Management also offers automation of tiering data into Glacier for long term archival at lower costs. This is easily configured and can be applied to both current and previous versions of objects.
Terminology
There are a few new terms that you will need to get to grips with if you plan on utilising AWS
- Buckets - A bucket is a place where you store your files. Think of a bucket as a directory within AWS. Each bucket requires a universal namespace which is completely unique globally. For example if I were to create a bucket called trekintech it would be found at http://trekintech.s3.amazonaws.com/
- Regions - A region within AWS is a geographical location upon which your data is stored. This is not only important for achieving optimal latency but also for ensuring you maintain control over your data by placing it only in regions where your legal team have advised is safe to do so. Each region is completely isolated from another.
- Availability Zones - An Availability Zone is a datacenter within a Region, Regions have multiple Availability Zones. Each Availability Zone is connected to others in that region via a low latency high speed link. This is the foundation for the extreme levels of durability S3 is able to offer.
Pricing
I don't intend to detail how much S3 costs on this post but I think it's worth explaining that the pricing structure isn't so straight forward as paying a cost per GB per month to store your data.
AWS will of course charge a cost per GB per month but additional to that there are also fees to put your data in and even higher fees to take it back out. To add to the complexity of the pricing AWS charge differently depending upon where you may be putting the data when you take it out. They also charge differently per service and region.
Above and beyond Cost per GB per Month you may see the below on your bill.
- GET, PUT, DELETE, COPY, POST, LIST requests (These are charges per action taken on your objects).
- Data Transfer In (Usually free on S3)
- Data Transfer Out
- Data Retrievals
- Lifecycle Transition Requests
Hopefully this provides a good intro into S3 - for those wanting more technical detail there will be a followup post.

